%pip install transformers sentencepiece -qqq > /dev/nullEnhancing Search Engine Performance: Addressing Vocabulary Mismatch with Machine Learning
Introduction
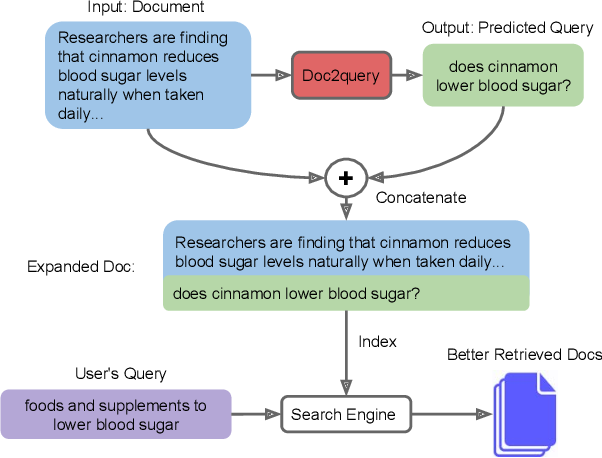
Search engines play a vital role in helping users find the information they need. However, a common challenge faced by search engines is the vocabulary mismatch problem. This occurs when the terms used by users in their queries do not precisely match the terms in the documents indexed by the search engine. (Eg: reduce vs lower though semantically mean the same, from the search engine stand point the terms are different). In summary the vocabulary used by users should match the vocabulary in the documents in the index. This is known as Vocabulary mismatch problem.
Document Expansion for Enhanced Matching
To predict the user questions on document text, we explore the varios ML models & approaches. Among them we explore popular approaches like Doc2Query, docTTTTTQuery etc. These models offer promising capabilities to generate relevant questions based on the contents of the documents.
To enhance the matching process between user queries and indexed documents, we use this technique called Document Expansion.By indexing these predicted user questions along with the documents we can augment the search results and improve the relevance.
The benefits of the approach is that computationally intensive tasks such as question prediction, are performed offline eliminating any additional overhead during search response times.
Tools for investigation are as follows
- Transformers library to load the model, tokenizers and to generate predictions
- HuggingFace Model Hub to load the pretrained models.
- PapersWithCode to investigate the literature.
Doc2Query
Most of the below are excerpts from this paper for my own reference.
Reference: Paper
Abstract: - One technique to improve the retrieval effectiveness of a search engine is to expand documents with terms that are related or representative of the documents’ content. - From the perspective of a question answering system, this might comprise questions the document can potentially answer. - Following this observation, we propose a simple method that predicts which queries will be issued for a given document and then expands it with those predictions with a vanilla sequence-to-sequence model, trained using datasets consisting of pairs of query and relevant documents. - By combining our method with a highly-effective re-ranking component, we achieve the state of the art in two retrieval tasks. - In a latency-critical regime, retrieval results alone (without re-ranking) approach the effectiveness of more computationally expensive neural re-rankers but are much faster.
Advantage
- primary advantage of this approach is that expensive neural inference is pushed to indexing time,
- “bag of words” queries are against an inverted index built on the augmented document collection.
Two important observations - Model tends to copy some words from the input document (e.g., Washington DC, River, chromosome), meaning that it can effectively perform term re-weighting (i.e., increasing the importance of key terms). - Nevertheless, the model also produces words not present in the input document (e.g., weather, relationship), which can be characterized as expansion by synonyms and other related terms.
Quote about T5 for doc expansion and the performance on BEIR dataset
In contrast, document expansion based docT5query is able to add new relevant keywords to a document and performs strong on the BEIR datasets. It outperforms BM25 on 11/18 datasets while providing a competitive performance on the remaining datasets.
Code
Here we are using pretrained T5 model from HuggingFace for document expansion.
As quoted in the model page
- Document expansion: You generate for your paragraphs 20-40 queries and index the paragraphs and the generates queries in a standard BM25 index like Elasticsearch, OpenSearch, or Lucene. The generated queries help to close the lexical gap of lexical search, as the generate queries contain synonyms. Further, it re-weights words giving important words a higher weight even if they appear seldomn in a paragraph. In our BEIR paper we showed that BM25+docT5query is a powerful search engine. In the BEIR repository we have an example how to use docT5query with Pyserini.
- Domain Specific Training Data Generation: It can be used to generate training data to learn an embedding model. On SBERT.net we have an example how to use the model to generate (query, text) pairs for a given collection of unlabeled texts. These pairs can then be used to train powerful dense embedding models.
# https://huggingface.co/doc2query/stackexchange-title-body-t5-small-v1
from transformers import T5Tokenizer, T5ForConditionalGeneration
model_name = 'doc2query/stackexchange-title-body-t5-small-v1'
tokenizer = T5Tokenizer.from_pretrained(model_name)
model = T5ForConditionalGeneration.from_pretrained(model_name)
text = "Python is an interpreted, high-level and general-purpose programming language. Python's design philosophy emphasizes code readability with its notable use of significant whitespace. Its language constructs and object-oriented approach aim to help programmers write clear, logical code for small and large-scale projects."
input_ids = tokenizer.encode(text, max_length=384, truncation=True, return_tensors='pt')
outputs = model.generate(
input_ids=input_ids,
max_length=64,
do_sample=True,
top_p=0.95,
num_return_sequences=5)
print("Text:")
print(text)
print("\nGenerated Queries:")
for i in range(len(outputs)):
query = tokenizer.decode(outputs[i], skip_special_tokens=True)
print(f'{i + 1}: {query}')Text:
Python is an interpreted, high-level and general-purpose programming language. Python's design philosophy emphasizes code readability with its notable use of significant whitespace. Its language constructs and object-oriented approach aim to help programmers write clear, logical code for small and large-scale projects.
Generated Queries:
1: What is Python's design philosophy?
2: What are the characteristics of Python?
3: What does "python's design philosophy" mean?
4: What is the difference between Python and Java?
5: What is the logic behind Python's programming languages?def generate(text: str):
input_ids = tokenizer.encode(text, max_length=384, truncation=True, return_tensors='pt')
outputs = model.generate(
input_ids=input_ids,
max_length=64,
do_sample=True,
top_p=0.95,
num_return_sequences=5)
print("Text:")
print(text)
gen_texts = []
print("\nGenerated Queries:")
for i in range(len(outputs)):
query = tokenizer.decode(outputs[i], skip_special_tokens=True)
#print(f'{i + 1}: {query}')
gen_texts.append(query)
return gen_textstext = 'In certain situations it is needed to have source code preprocessed by `gcc` without undergoing the full compilation process. For example, this might be necessary when embedded SQL is included in C or C++ programs and the preprocesssed file will be passed on to another tool which will convert the SQL in native source code. - Red Hat Enterprise Linux (RHEL) --- ***Disclaimer:** Links contained herein to an external website(s) are provided for convenience only. Red Hat has not reviewed the links and is not responsible for the content or its availability. The inclusion of any link to an external website does not imply endorsement by Red Hat of the website or their entities, products or services. You agree that Red Hat is not responsible or liable for any loss or expenses that may result due to your use of (or reliance on) the external site or content.*--- To make GCC stop after the preprocessing stage, use the option `-E`, as explained in [GNU- GCC options](https://gcc.gnu.org/onlinedocs/gcc/Overall-Options.html#Overall-Options). In other words, Using the `-E` parameter with `gcc` or `g++` will produce **only** the preprocessed source code: $ gcc-E program.c-o program.preprocessed The `program.preprocessed` file will contain the file preprocessed by `gcc` (`Macros` will be expanded and all include files will be resolved). This preprocessed output will contain lines such as the following ones: ~~~ # 131 "/usr/include/bits/types.h" 3 4 # 1 "/usr/include/bits/typesizes.h" 1 3 4 # 132 "/usr/include/bits/types.h" 2 3 4 ~~~ These lines are line markers that show from which include files specific source code was taken. If those lines are not desired run the same command adding the `-P` parameter: $ gcc-E-P program.c-o program.preprocessed'
generate(text)Text:
In certain situations it is needed to have source code preprocessed by `gcc` without undergoing the full compilation process. For example, this might be necessary when embedded SQL is included in C or C++ programs and the preprocesssed file will be passed on to another tool which will convert the SQL in native source code. - Red Hat Enterprise Linux (RHEL) --- ***Disclaimer:** Links contained herein to an external website(s) are provided for convenience only. Red Hat has not reviewed the links and is not responsible for the content or its availability. The inclusion of any link to an external website does not imply endorsement by Red Hat of the website or their entities, products or services. You agree that Red Hat is not responsible or liable for any loss or expenses that may result due to your use of (or reliance on) the external site or content.*--- To make GCC stop after the preprocessing stage, use the option `-E`, as explained in [GNU- GCC options](https://gcc.gnu.org/onlinedocs/gcc/Overall-Options.html#Overall-Options). In other words, Using the `-E` parameter with `gcc` or `g++` will produce **only** the preprocessed source code: $ gcc-E program.c-o program.preprocessed The `program.preprocessed` file will contain the file preprocessed by `gcc` (`Macros` will be expanded and all include files will be resolved). This preprocessed output will contain lines such as the following ones: ~~~ # 131 "/usr/include/bits/types.h" 3 4 # 1 "/usr/include/bits/typesizes.h" 1 3 4 # 132 "/usr/include/bits/types.h" 2 3 4 ~~~ These lines are line markers that show from which include files specific source code was taken. If those lines are not desired run the same command adding the `-P` parameter: $ gcc-E-P program.c-o program.preprocessed
Generated Queries:['Make GCC stop after preprocessing',
'GCC: how to stop "gcc" after the full compilation process?',
'Retrieving Source code preprocessed by gcc without undergoing full compilation process',
"Why can't I make GCC stop after the full compilation process?",
'Can the -E parameter for gcc or g++ prevent any preprocessed source code from being loaded?']text = 'Why gpxe boot fails when next-server details are offered by the second dhcp server in Red Hat Enterprise Linux 6 ? * Why gpxe boot fails when next-server details are offered by the second dhcp server in Red Hat Enterprise Linux 6? Fails with the following message ~~~ ftp://X.X.X.X/Bootstrap \\X86PC\\BStrap.0... Permission denied (0x0212603c) ~~~ * Red Hat Enterprise Linux 6 * KVM GPXe boot * Two dhcp servers on different subnet and are accessed via relay agetns First dhcp server assign IP address Second dhcp server provides next-server details If gpxe is used to pxe-boot a KVM guest, it uses the next-server from the first dhcp offer and if it fails, then does not re-try with the next-server option provided in the second dhcp server offer packet Update gpxe packages to below versions or above.- gpxe-bootimgs-0.9.7-6.10.el6.noarch.rpm- gpxe-roms-0.9.7-6.10.el6.noarch.rpm- gpxe-roms-qemu-0.9.7-6.10.el6.noarch.rpm This has been fixed by errata http://rhn.redhat.com/errata/RHBA-2013-1628.html'
generate(text)Text:
Why gpxe boot fails when next-server details are offered by the second dhcp server in Red Hat Enterprise Linux 6 ? * Why gpxe boot fails when next-server details are offered by the second dhcp server in Red Hat Enterprise Linux 6? Fails with the following message ~~~ ftp://X.X.X.X/Bootstrap \X86PC\BStrap.0... Permission denied (0x0212603c) ~~~ * Red Hat Enterprise Linux 6 * KVM GPXe boot * Two dhcp servers on different subnet and are accessed via relay agetns First dhcp server assign IP address Second dhcp server provides next-server details If gpxe is used to pxe-boot a KVM guest, it uses the next-server from the first dhcp offer and if it fails, then does not re-try with the next-server option provided in the second dhcp server offer packet Update gpxe packages to below versions or above.- gpxe-bootimgs-0.9.7-6.10.el6.noarch.rpm- gpxe-roms-0.9.7-6.10.el6.noarch.rpm- gpxe-roms-qemu-0.9.7-6.10.el6.noarch.rpm This has been fixed by errata http://rhn.redhat.com/errata/RHBA-2013-1628.html
Generated Queries:['gpxe boot fails when next-server details are offered by the second dhcp server',
'gpxe boot fails when next-server details are offered by the second dhcp server in Red Hat Enterprise Linux 6?',
'gpxe boot fails when next-server details are offered by the second dhcp server in Red Hat Enterprise Linux 6',
'gpxe boot fails when next-server details are offered by the second dhcp server in Red Hat Enterprise Linux 6?',
'Why gpxe boot fails when next-server details are offered by the second dhcp server in Red Hat Enterprise Linux 6?']If I provide the title included in the contents, the generated text replicates the title.
text = 'Unable change permission to NFS share mounted at the client. * The permissions for files can be changed inside the NFS share, but the directory permissions cannot be changed, even by using root at the client. * Here is an example of the failure, which includes the NFS client mount options: ~~~ # mount | grep nfs nfsd on /proc/fs/nfsd type nfsd (rw) 1.1.1.253:/xyz/export on /opt/oracle/foobar002 type nfs (rw,user=oracle,noexec,nosuid,nodev,user,noac,nfsvers=3,tcp,rsize=1048576,wsize=1048576,addr=1.1.1.253) # ls-ld /opt/oracle/foobar002 drwxrwxrwx 2 root root 2048 Mar 19 09:52 /opt/oracle/foobar002 $ touch /opt/oracle/foobar002/oracle-test.txt $ ls-l /opt/oracle/foobar002/ total 0-rw-r--r-- 1 oracle oinstall 0 Mar 19 15:19 oracle-test.txt-rw-rw-r-- 1 myuidgid myuidgid 0 Mar 19 15:18 test-2.txt-rw-r--r-- 1 4294967294 4294967294 0 Mar 19 15:17 test.txt # chown oracle /opt/oracle/foobar002/ chown: changing ownership of `/opt/oracle/foobar002/': Operation not permitted ~~~ * Red Hat Enterprise Linux 5.6 * NFS client * NFS server * /etc/exports: ~~~ /xyz/export *(sync,rw,root_squash,anonuid=4294967294,anongid=4294967294,no_subtree_check,anonuid=4294967294,anongid=4294967294,fsid=29247) ~~~ * Gather sosreport or export options ("showmount-e" from NFS client or /etc/export file from the NFS server). * Here were the options seen: /xyz/export *(sync,rw,root_squash,anonuid=4294967294,anongid=4294967294,no_subtree_check,anonuid=4294967294,anongid=4294967294,fsid=29247) * Noted the following: 1) Anongid/anonuid was used twice. 2) root_squash is used which means request from root will also be mapped to anonuid=429496729, so trying to change as root id will also not work. 3) check the correct anonuid and anongid both at the server and client side, they should match both on server as well as client side. * The anonuid and anongid at the server and client side did not match. * Corrected the anonuid and anongid while exporting the NFS share at the NFS server.'
generate(text)Text:
Unable change permission to NFS share mounted at the client. * The permissions for files can be changed inside the NFS share, but the directory permissions cannot be changed, even by using root at the client. * Here is an example of the failure, which includes the NFS client mount options: ~~~ # mount | grep nfs nfsd on /proc/fs/nfsd type nfsd (rw) 1.1.1.253:/xyz/export on /opt/oracle/foobar002 type nfs (rw,user=oracle,noexec,nosuid,nodev,user,noac,nfsvers=3,tcp,rsize=1048576,wsize=1048576,addr=1.1.1.253) # ls-ld /opt/oracle/foobar002 drwxrwxrwx 2 root root 2048 Mar 19 09:52 /opt/oracle/foobar002 $ touch /opt/oracle/foobar002/oracle-test.txt $ ls-l /opt/oracle/foobar002/ total 0-rw-r--r-- 1 oracle oinstall 0 Mar 19 15:19 oracle-test.txt-rw-rw-r-- 1 myuidgid myuidgid 0 Mar 19 15:18 test-2.txt-rw-r--r-- 1 4294967294 4294967294 0 Mar 19 15:17 test.txt # chown oracle /opt/oracle/foobar002/ chown: changing ownership of `/opt/oracle/foobar002/': Operation not permitted ~~~ * Red Hat Enterprise Linux 5.6 * NFS client * NFS server * /etc/exports: ~~~ /xyz/export *(sync,rw,root_squash,anonuid=4294967294,anongid=4294967294,no_subtree_check,anonuid=4294967294,anongid=4294967294,fsid=29247) ~~~ * Gather sosreport or export options ("showmount-e" from NFS client or /etc/export file from the NFS server). * Here were the options seen: /xyz/export *(sync,rw,root_squash,anonuid=4294967294,anongid=4294967294,no_subtree_check,anonuid=4294967294,anongid=4294967294,fsid=29247) * Noted the following: 1) Anongid/anonuid was used twice. 2) root_squash is used which means request from root will also be mapped to anonuid=429496729, so trying to change as root id will also not work. 3) check the correct anonuid and anongid both at the server and client side, they should match both on server as well as client side. * The anonuid and anongid at the server and client side did not match. * Corrected the anonuid and anongid while exporting the NFS share at the NFS server.
Generated Queries:['Unable change permission to NFS share mounted at the client',
'Unable change permission to NFS share mounted at the client',
'NFS client "Unable change permission to NFS share mounted at the client."',
'Unable change permission to NFS share mounted at the client',
'Unable change permission to NFS share mounted at the client']Exclude the title. Provides much better variations.
text = '* The permissions for files can be changed inside the NFS share, but the directory permissions cannot be changed, even by using root at the client. * Here is an example of the failure, which includes the NFS client mount options: ~~~ # mount | grep nfs nfsd on /proc/fs/nfsd type nfsd (rw) 1.1.1.253:/xyz/export on /opt/oracle/foobar002 type nfs (rw,user=oracle,noexec,nosuid,nodev,user,noac,nfsvers=3,tcp,rsize=1048576,wsize=1048576,addr=1.1.1.253) # ls-ld /opt/oracle/foobar002 drwxrwxrwx 2 root root 2048 Mar 19 09:52 /opt/oracle/foobar002 $ touch /opt/oracle/foobar002/oracle-test.txt $ ls-l /opt/oracle/foobar002/ total 0-rw-r--r-- 1 oracle oinstall 0 Mar 19 15:19 oracle-test.txt-rw-rw-r-- 1 myuidgid myuidgid 0 Mar 19 15:18 test-2.txt-rw-r--r-- 1 4294967294 4294967294 0 Mar 19 15:17 test.txt # chown oracle /opt/oracle/foobar002/ chown: changing ownership of `/opt/oracle/foobar002/': Operation not permitted ~~~ * Red Hat Enterprise Linux 5.6 * NFS client * NFS server * /etc/exports: ~~~ /xyz/export *(sync,rw,root_squash,anonuid=4294967294,anongid=4294967294,no_subtree_check,anonuid=4294967294,anongid=4294967294,fsid=29247) ~~~ * Gather sosreport or export options ("showmount-e" from NFS client or /etc/export file from the NFS server). * Here were the options seen: /xyz/export *(sync,rw,root_squash,anonuid=4294967294,anongid=4294967294,no_subtree_check,anonuid=4294967294,anongid=4294967294,fsid=29247) * Noted the following: 1) Anongid/anonuid was used twice. 2) root_squash is used which means request from root will also be mapped to anonuid=429496729, so trying to change as root id will also not work. 3) check the correct anonuid and anongid both at the server and client side, they should match both on server as well as client side. * The anonuid and anongid at the server and client side did not match. * Corrected the anonuid and anongid while exporting the NFS share at the NFS server.'
generate(text)Text:
* The permissions for files can be changed inside the NFS share, but the directory permissions cannot be changed, even by using root at the client. * Here is an example of the failure, which includes the NFS client mount options: ~~~ # mount | grep nfs nfsd on /proc/fs/nfsd type nfsd (rw) 1.1.1.253:/xyz/export on /opt/oracle/foobar002 type nfs (rw,user=oracle,noexec,nosuid,nodev,user,noac,nfsvers=3,tcp,rsize=1048576,wsize=1048576,addr=1.1.1.253) # ls-ld /opt/oracle/foobar002 drwxrwxrwx 2 root root 2048 Mar 19 09:52 /opt/oracle/foobar002 $ touch /opt/oracle/foobar002/oracle-test.txt $ ls-l /opt/oracle/foobar002/ total 0-rw-r--r-- 1 oracle oinstall 0 Mar 19 15:19 oracle-test.txt-rw-rw-r-- 1 myuidgid myuidgid 0 Mar 19 15:18 test-2.txt-rw-r--r-- 1 4294967294 4294967294 0 Mar 19 15:17 test.txt # chown oracle /opt/oracle/foobar002/ chown: changing ownership of `/opt/oracle/foobar002/': Operation not permitted ~~~ * Red Hat Enterprise Linux 5.6 * NFS client * NFS server * /etc/exports: ~~~ /xyz/export *(sync,rw,root_squash,anonuid=4294967294,anongid=4294967294,no_subtree_check,anonuid=4294967294,anongid=4294967294,fsid=29247) ~~~ * Gather sosreport or export options ("showmount-e" from NFS client or /etc/export file from the NFS server). * Here were the options seen: /xyz/export *(sync,rw,root_squash,anonuid=4294967294,anongid=4294967294,no_subtree_check,anonuid=4294967294,anongid=4294967294,fsid=29247) * Noted the following: 1) Anongid/anonuid was used twice. 2) root_squash is used which means request from root will also be mapped to anonuid=429496729, so trying to change as root id will also not work. 3) check the correct anonuid and anongid both at the server and client side, they should match both on server as well as client side. * The anonuid and anongid at the server and client side did not match. * Corrected the anonuid and anongid while exporting the NFS share at the NFS server.
Generated Queries:['SSH NFS clients permissions can be changed, even by using root',
'NFS: root permissions not changing',
"Why can't the directory permissions be changed in the NFS share?",
'NFS share fails to resolve NFS: directory permissions cannot be changed',
'How can I set NFS permissions to be changed with root?']text = '- qpid process segfaulting with backtrace attached- basic usage of the broker is sending and receiving messages in transactions, with optional message release or rejection in a consumer - MRG Messaging 2.0 or older - coredump has this backtrace (particular line numbers refer to qpid 0.10): ~~~ #0 qpid::framing::FrameSet::getContentSize (this=0x128) at qpid/framing/FrameSet.cpp:82 #1 0x00002aaaaae9ca9c in qpid::broker::QueuePolicy::dequeued (this=0x9e29b0, m=...) at qpid/broker/QueuePolicy.cpp:105 #2 0x00002aaaaae856b9 in qpid::broker::Queue::dequeued (this=0x9e1ca0, msg=...) at qpid/broker/Queue.cpp:709 #3 0x00002aaaaae8a8a0 in qpid::broker::Queue::dequeueCommitted (this=0x9e1ca0, msg=...) at qpid/broker/Queue.cpp:685 #4 0x00002aaaaaef3bb5 in operator() (this=0x9e17c0) at /usr/include/boost/bind/mem_fn_template.hpp:104... ~~~ Complete backtrace is attached- reproducer: * send a message to some queue * within a transaction: fetch a message, release it and commit the transaction/session- see attached C++ source code reproducer: ~~~./transacted_release ~~~ - there is a bug in processing message release within a transaction of a consumer- the released message is not moved away from the list of messages sent to the consumer within a transaction- so when the consumer commits the transaction, a removal of already released message is attempted, what fails with pointing to 0x0 address - upgrade to (at least) MRG 2.1 (that is qpid 0.14)'.lower()
generate(text)Text:
- qpid process segfaulting with backtrace attached- basic usage of the broker is sending and receiving messages in transactions, with optional message release or rejection in a consumer - mrg messaging 2.0 or older - coredump has this backtrace (particular line numbers refer to qpid 0.10): ~~~ #0 qpid::framing::frameset::getcontentsize (this=0x128) at qpid/framing/frameset.cpp:82 #1 0x00002aaaaae9ca9c in qpid::broker::queuepolicy::dequeued (this=0x9e29b0, m=...) at qpid/broker/queuepolicy.cpp:105 #2 0x00002aaaaae856b9 in qpid::broker::queue::dequeued (this=0x9e1ca0, msg=...) at qpid/broker/queue.cpp:709 #3 0x00002aaaaae8a8a0 in qpid::broker::queue::dequeuecommitted (this=0x9e1ca0, msg=...) at qpid/broker/queue.cpp:685 #4 0x00002aaaaaef3bb5 in operator() (this=0x9e17c0) at /usr/include/boost/bind/mem_fn_template.hpp:104... ~~~ complete backtrace is attached- reproducer: * send a message to some queue * within a transaction: fetch a message, release it and commit the transaction/session- see attached c++ source code reproducer: ~~~./transacted_release ~~~ - there is a bug in processing message release within a transaction of a consumer- the released message is not moved away from the list of messages sent to the consumer within a transaction- so when the consumer commits the transaction, a removal of already released message is attempted, what fails with pointing to 0x0 address - upgrade to (at least) mrg 2.1 (that is qpid 0.14)
Generated Queries:['qpid process segfaulting with backtrace attached',
'qpid segfaulting with backtrace attached',
'Can anyone help me with my data segfaulting qpid transaction?',
'qpid segfault with backtrace attached- coredump has mrg messaging 2.0',
'qpid process segfaulting with backtrace attached - coredump']Some post-processing required such lower casing in order to generate unique text.
Exclude the issue statements
text = '- basic usage of the broker is sending and receiving messages in transactions, with optional message release or rejection in a consumer - MRG Messaging 2.0 or older - coredump has this backtrace (particular line numbers refer to qpid 0.10): ~~~ #0 qpid::framing::FrameSet::getContentSize (this=0x128) at qpid/framing/FrameSet.cpp:82 #1 0x00002aaaaae9ca9c in qpid::broker::QueuePolicy::dequeued (this=0x9e29b0, m=...) at qpid/broker/QueuePolicy.cpp:105 #2 0x00002aaaaae856b9 in qpid::broker::Queue::dequeued (this=0x9e1ca0, msg=...) at qpid/broker/Queue.cpp:709 #3 0x00002aaaaae8a8a0 in qpid::broker::Queue::dequeueCommitted (this=0x9e1ca0, msg=...) at qpid/broker/Queue.cpp:685 #4 0x00002aaaaaef3bb5 in operator() (this=0x9e17c0) at /usr/include/boost/bind/mem_fn_template.hpp:104... ~~~ Complete backtrace is attached- reproducer: * send a message to some queue * within a transaction: fetch a message, release it and commit the transaction/session- see attached C++ source code reproducer: ~~~./transacted_release ~~~ - there is a bug in processing message release within a transaction of a consumer- the released message is not moved away from the list of messages sent to the consumer within a transaction- so when the consumer commits the transaction, a removal of already released message is attempted, what fails with pointing to 0x0 address - upgrade to (at least) MRG 2.1 (that is qpid 0.14)'.lower()
generate(text)Text:
- basic usage of the broker is sending and receiving messages in transactions, with optional message release or rejection in a consumer - mrg messaging 2.0 or older - coredump has this backtrace (particular line numbers refer to qpid 0.10): ~~~ #0 qpid::framing::frameset::getcontentsize (this=0x128) at qpid/framing/frameset.cpp:82 #1 0x00002aaaaae9ca9c in qpid::broker::queuepolicy::dequeued (this=0x9e29b0, m=...) at qpid/broker/queuepolicy.cpp:105 #2 0x00002aaaaae856b9 in qpid::broker::queue::dequeued (this=0x9e1ca0, msg=...) at qpid/broker/queue.cpp:709 #3 0x00002aaaaae8a8a0 in qpid::broker::queue::dequeuecommitted (this=0x9e1ca0, msg=...) at qpid/broker/queue.cpp:685 #4 0x00002aaaaaef3bb5 in operator() (this=0x9e17c0) at /usr/include/boost/bind/mem_fn_template.hpp:104... ~~~ complete backtrace is attached- reproducer: * send a message to some queue * within a transaction: fetch a message, release it and commit the transaction/session- see attached c++ source code reproducer: ~~~./transacted_release ~~~ - there is a bug in processing message release within a transaction of a consumer- the released message is not moved away from the list of messages sent to the consumer within a transaction- so when the consumer commits the transaction, a removal of already released message is attempted, what fails with pointing to 0x0 address - upgrade to (at least) mrg 2.1 (that is qpid 0.14)
Generated Queries:['coredump for mrg messaging in coredump',
'coredump backtrace problem with messaging 2.0',
'mrg messaging, coredump and coredump',
'mrg messaging 1.1 and coredump: why is the backtrace not used?',
'Why has my backAmplitude (_0) returned?']text = 'We are passing through a migration from EPP with SP 5.1 to EPP with SP 5.2.0 we noticed some strange behaviors. For example, the context menu in "Content Explorer" is all messed. How can we solve this? - Red Hat JBoss Portal Platform (JPP also known as EPP)- 5.2.0- Site Publisher (SP)- 5.2.0 In Site Publisher Groovy templates are also contents from JCR (JCR nodes). When we are passing through a migration we need to keep the JCR shared folder and do not change it. It causes that some Groovy templates from the old installation are not correctly replaced to the new ones, which leads to compatibility issues with EPP+SP 5.2. Upgrade to newest EPP 5.2.x release and [migrate all templates to the new version](https://access.redhat.com/site/solutions/85613).'
generate(text)Text:
We are passing through a migration from EPP with SP 5.1 to EPP with SP 5.2.0 we noticed some strange behaviors. For example, the context menu in "Content Explorer" is all messed. How can we solve this? - Red Hat JBoss Portal Platform (JPP also known as EPP)- 5.2.0- Site Publisher (SP)- 5.2.0 In Site Publisher Groovy templates are also contents from JCR (JCR nodes). When we are passing through a migration we need to keep the JCR shared folder and do not change it. It causes that some Groovy templates from the old installation are not correctly replaced to the new ones, which leads to compatibility issues with EPP+SP 5.2. Upgrade to newest EPP 5.2.x release and [migrate all templates to the new version](https://access.redhat.com/site/solutions/85613).
Generated Queries:['Migrate from EPP to SP 5.2 has strange behavior',
'Magento migration for a different version from SharePoint with new environment is messed up',
'Disable JCR contents with custom templates, SP 5.1 to EPP + SP 5.2.0',
'Migrating JCR and context menu messes',
'JCR menu of JCR-Node is corrupted']Refactor
Refactor the code for reusability and also instead use Auto classes from transformers to load the Sequence 2 Sequence model.
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
import torch
from typing import List
class QueryGenerator:
def __init__(self, model_path:str, use_fast:bool=False):
self.tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=use_fast)
self.model = AutoModelForSeq2SeqLM.from_pretrained(model_path)
def generate(self, text: str, max_length:int=384, output_length=64, num_return_sequences:int=5, top_p:float=0.95)->List[str]:
input_ids = self.tokenizer.encode(text, max_length=max_length, truncation=True, return_tensors='pt')
with torch.no_grad():
outputs = self.model.generate(
input_ids=input_ids,
max_length=output_length,
do_sample=True,
top_p=top_p,
num_return_sequences=num_return_sequences)
return self.tokenizer.batch_decode(outputs, skip_special_tokens=True)text = 'In certain situations it is needed to have source code preprocessed by `gcc` without undergoing the full compilation process. For example, this might be necessary when embedded SQL is included in C or C++ programs and the preprocesssed file will be passed on to another tool which will convert the SQL in native source code. - Red Hat Enterprise Linux (RHEL) --- ***Disclaimer:** Links contained herein to an external website(s) are provided for convenience only. Red Hat has not reviewed the links and is not responsible for the content or its availability. The inclusion of any link to an external website does not imply endorsement by Red Hat of the website or their entities, products or services. You agree that Red Hat is not responsible or liable for any loss or expenses that may result due to your use of (or reliance on) the external site or content.*--- To make GCC stop after the preprocessing stage, use the option `-E`, as explained in [GNU- GCC options](https://gcc.gnu.org/onlinedocs/gcc/Overall-Options.html#Overall-Options). In other words, Using the `-E` parameter with `gcc` or `g++` will produce **only** the preprocessed source code: $ gcc-E program.c-o program.preprocessed The `program.preprocessed` file will contain the file preprocessed by `gcc` (`Macros` will be expanded and all include files will be resolved). This preprocessed output will contain lines such as the following ones: ~~~ # 131 "/usr/include/bits/types.h" 3 4 # 1 "/usr/include/bits/typesizes.h" 1 3 4 # 132 "/usr/include/bits/types.h" 2 3 4 ~~~ These lines are line markers that show from which include files specific source code was taken. If those lines are not desired run the same command adding the `-P` parameter: $ gcc-E-P program.c-o program.preprocessed'
print("Text:")
print(text)
print("\nGenerated Queries:")
model_name = 'doc2query/stackexchange-title-body-t5-small-v1'
qGen = QueryGenerator(model_path=model_name)
qGen.generate(text, num_return_sequences=5)Conclusion
This post should serve as the initial starting point for the Document Expansion technique and Refer the Colbert paper for the results using these approaches in standard benchmarks such as BEIR. In order to use these technique in your domain, index your documents using tools such as pyserini and compare with BM25 baseline.