fastclean
Experiments to find incorrect labels in the dataset and noisy training
Motivation
-
Large public and real world datasets can have incorrect labels. These large datasets are hand labeled using human-annotation such as Mechanical Turks or even generated by automated systems based on user actions rather than explicitly added by experts. In case of medical domains, the time spent by specialists or experts for labeling is highly expensive. Hence there is a tradeoff between cost of labeling and the quality of the labels.
-
Using deep learning models trained on these large datasets containing noisy labels can cause the model to overfit on these incorrect labels impacting the performance measure. Also test set used to determine the performance measure should be without any label errors.
-
It is critical to detect the extent of mislabeling, identify the noisy indices and take corrective actions. The corrective actions could include removing the noisy labels, correcting the noisy samples or make the model more robust to noisy labels in order to improve the performance.
-
Depending upon the extent of noise and relabeling cost, it may or may not be feasible to do the complete relabeling efforts. But we can prioritize the labels that are incorrectly labeled based on model confidence (say greater than 0.9)

Approaches
- Confident Learning
Confident learning (CL) is an approach focusing on label quality by characterizing and identifying label errors in datasets, based on the principles of pruning noisy data, counting with probabilistic thresholds to estimate noise, and ranking examples to train with confidence.
Pruning could be based on 1. Confident Examples that are labelled correctly with high probability & pruning the rest 2. Confident Errors that are labeled incorrectly with high probability of belonging to a different class and hence pruned.
-
LabelSmoothing is an effective technique for regularization when we have imperfectly labeled data due to annotators disagreeing on the category. It ensures the loss function to be more robust to incorrect labels.
-
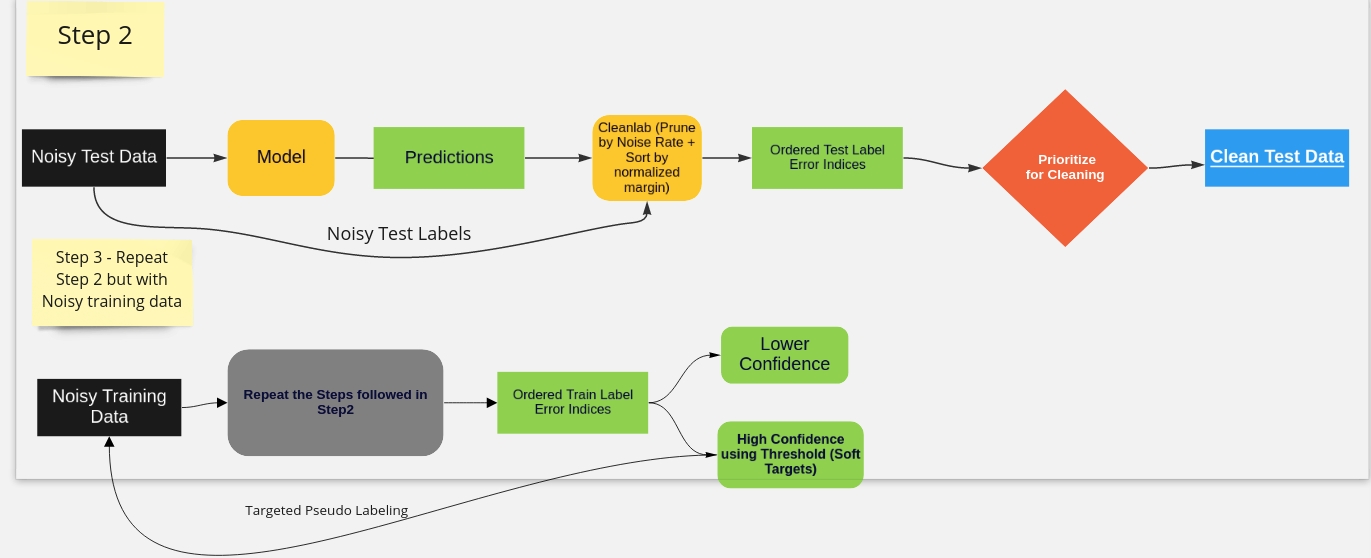
Targeted Pseudo Labeling : Noisy Samples identified with high confidence can be reused with their predictions as pseudolabels (Confident Errors).
-
Integrating cleanlab with fastai Interpretation module4 for reviewing the noisy labels present in train, valid and test.
Takeaways
Pretrained Model as effective feature extractors + Gradual Unfreezing + Label Smoothing
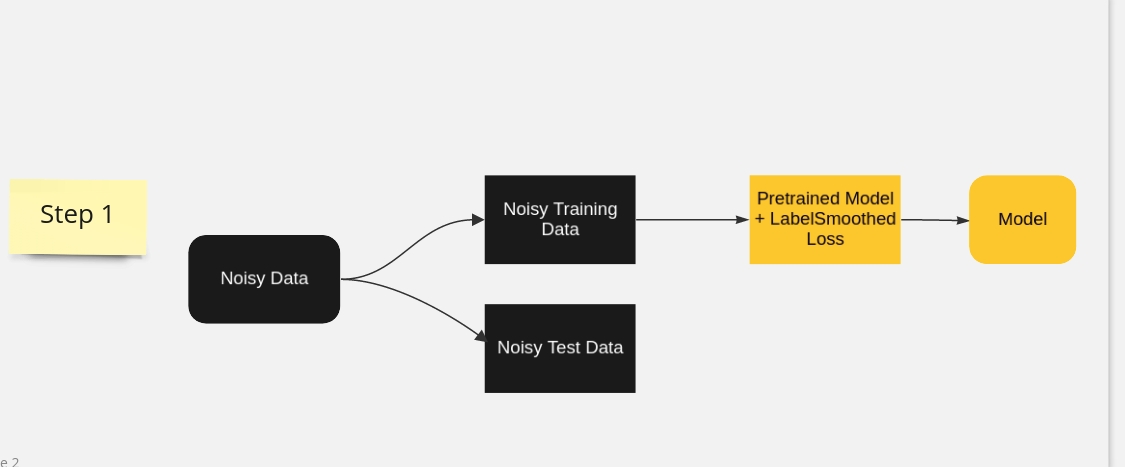
Ensure Clean Test data & Reduce noise impact on train data with Pseudo Labeling
Datasets
- Experiments are conducted for classification tasks in vision and text.
Noisy Imagenette
This contains a subset of images from Imagenet on 10 different classes. Please refer[1] on the generation of noisy labels. In order to effectively compare the evaluation, the validation set is clean & the labels are not changed.
Covid Tweets (Noisy User Generated Text)
The dataset from WNUT-2020 Task 2: Identification of informative COVID-19 English Tweets is used to evaluate the noisy samples identification from the test set. The goal of the task is to automatically identify whether an English Tweet related to the novel coronavirus (COVID-19) is informative or not. Such informative Tweets provide information about recovered, suspected, confirmed and death cases as well as location or travel history of the cases.
Notebooks
- 01 - Training using Noisy Imagenette[1], a noisy version of fastai Imagenette.
- In this notebook noisy imagenette is used to perform experiments and compare the techniques on various noise levels ranging 1/5/25/50 percent levels
- Training using Resnet 18 and Resnet 34 with Gradual Unfreezing using fastai.
- Detecting Noise Indices in the training data using Confident Learning using Cleanlab [2]
- Pseudo Labeling using High Confident Predictions as soft targets
- 02 - Training MNIST with LabelSmoothing using CleanLab and reproduce the result.
-
03 - Text Classification on Covid Tweets to identify the informativeness. We wanted to identify the noisy labels present in the test set.
- 04 - Integrate fastai Intepretation module with cleanlab to identify and review the noisy labels in training, validation and test dataset.
Scripts
- Noisy Imagenette : fsdl/train.py
- Covid Tweets : fsdl/covidtweets.py
Outputs
- Noisy Labels detected from Imagenette with & without LabelSmoothing
- Data Directory
├── imagenette_labelsmoothing
│ ├── prune_noise_rate
│ │ ├── noisy25_train_predictions.csv
│ │ ├── noisy50_train_predictions.csv
│ │ └── noisy5_train_predictions.csv
│ └── prune_noise_rate_class
│ ├── noisy25_train_predictions.csv
│ ├── noisy50_train_predictions.csv
│ └── noisy5_train_predictions.csv
└── imagenette_no_labelsmoothing
├── prune_noise_rate
│ ├── noisy25_train_predictions.csv
│ ├── noisy50_train_predictions.csv
│ └── noisy5_train_predictions.csv
└── prune_noise_rate_class
├── noisy25_train_predictions.csv
├── noisy50_train_predictions.csv
└── noisy5_train_predictions.csv
- Covid Tweets : Noisy Labels Detected from Test Data can be viewed using Streamlit

covid
├── noisy
└── noisy_text.csv
Experiments
Noisy Imagenette
- Resnet 34 Pretrained with ImageNet
- Experiment Tracking using Weights & Biases
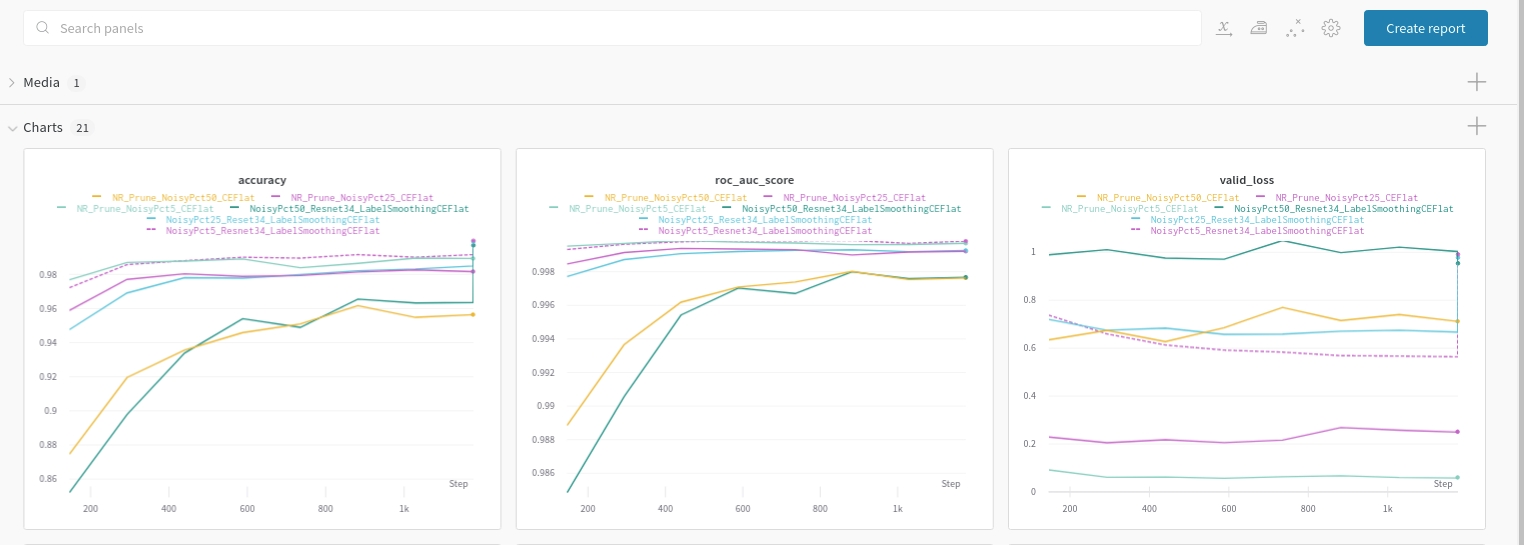
| Noice Percent | Actual Noisy samples | Noise with Label Smoothing ( prune by noise rate) | Noise with Label Smoothing ( prune by noise rate + class ) | Noise with CrossEntropy (prune by noise rate) | Noise with CrossEntropy (prune by noise rate + class) |
|---|---|---|---|---|---|
| 5% | 114 | 117 | 76 | 431 | 406 |
| 25% | 2122 | 2177 | 2023 | 2217 | 2140 |
| 50% | 4092 | 4256 | 4132 | 4257 | 4151 |
StreamLit
- Demo of Covid Informativeness on Noisy Tweet Predictions is available in assets directory streamlit-st_app-2021-05-12-16-05-67.webm.
References
- [1] Introducing Noisy Imagenette
- [2] Confident Learning: Estimate Uncertainty in Dataset Labels
- [3] WNUT-2020 Task 2: Identification of informative COVID-19 English Tweets
- [4] Interpretation of Predictions
- [5] An Introduction to Confident Learning: Finding and Learning with Label Errors in Datasets
- [6] Pervasive Label Errors in ML Datasets Destabilize Benchmarks