Paper Summary - Rapidly Deploying a Neural Search Engine for the COVID-19 Open Research Dataset
Overview of covidex.ai
This is a paper summary of deploying a Neural Search Engine to answer questions from the COVID-19 dataset.
Neural Covidex applies state-of-the-art neural network models and artificial intelligence (AI) techniques to answer questions using the COVID-19 Open Research Dataset (CORD-19) provided by the Allen Institute for AI (data release of April 3, 2020). This project is led by Jimmy Lin from the University of Waterloo and Kyunghyun Cho from NYU, with a small team of wonderful students: Edwin Zhang and Nikhil Gupta. Special thanks to Colin Raffel for his help in pretraining T5 models for the biomedical domain.”
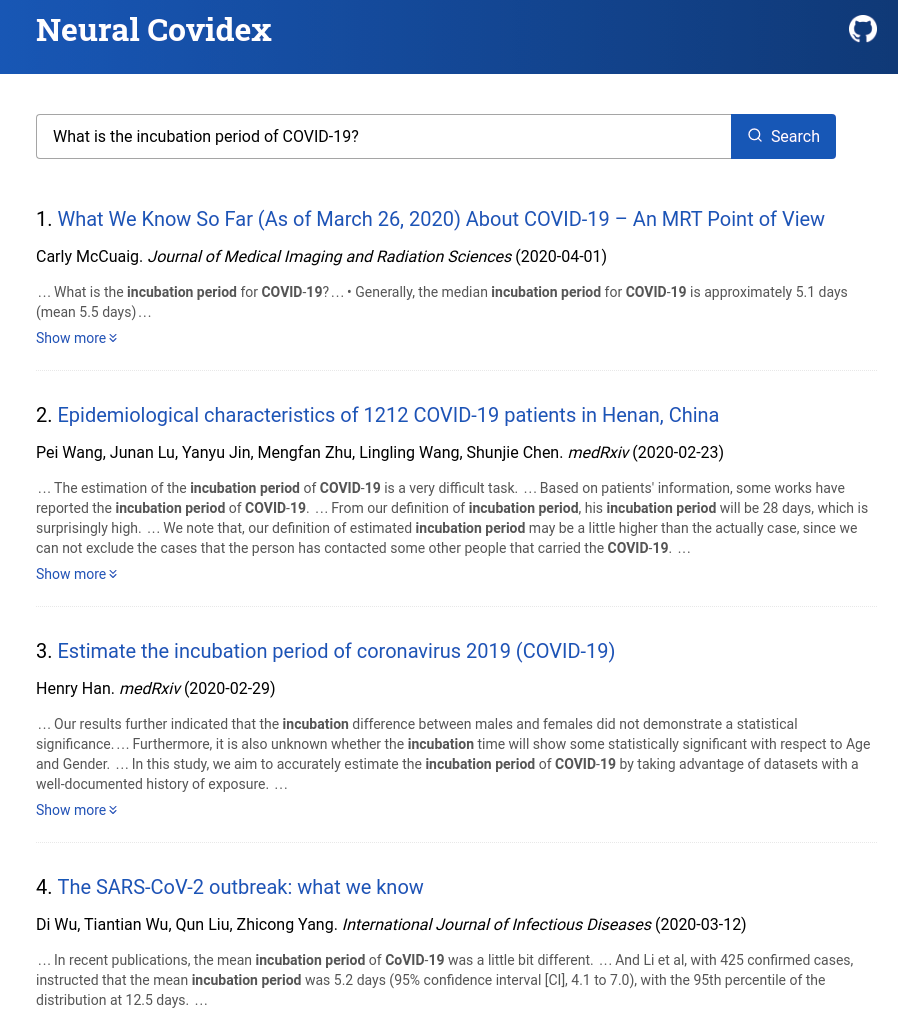
Motivation
The ongoing pandemic crisis poses a huge challenge to get timely information for public health officials, clinicians, researchers, virologists. In order to respond to this challenge, Allen AI publishes a COVID-19 data set (CORD-19) in collaboration with other research groups. The source for this data set is both research articles published about coronovirus and other related research articles. The aim of this effort is to bring researchers
- to apply language processing techniques in order to generate insights & make data driven decisions.
- to provide ways for the front line to consume the recent developments in a digestible form & apply in the field.
Outcomes
Jimmy Lin & his research team responded to this call. The two strategies adopted were
- Real time users should be able to find answers to any questions associated with COVID
- Other Researchers should be able reuse the components they build. Providing a modular and reusable components is set as part of the requirements.
The team decided to build end to end real time search application called covidex.ai . They developed the components that powers this engine in a short span of time for the information retrieval need .
- keyword based search interface : This also provides faceted navigation in the form of filters like author, article source, time range and highlighting words from the results that matches with user query.
- neural ranking component that sorts the results with the top most results answering user’s question.
Background & Related Work
Traditional search architecture comprises of two phases Content Indexing and Keyword Searching. During indexing, content is transformed into an Indexable form called as Document The search engine convert this document into a fundamental data structure called as Inverted Index. This is similar to what you see in Book Appendix where terms are mapped towards the pages. Similarly Inverted index contains terms mapped towards docIds where the term appears & position in the document.
Searching phase is further divided into two stages retrieval stage and ranking stage. In the first stage, given a search term(s) you will retrieve the list of matching documents from the inverted index. In the second stage, the matched documents are sorted based on the computed relevance score.
Modern Search Architectures
More modern multi-stage search architectures from Bing & Alibaba expand the Search Phase with additional reranking stages. Except for the first retrieval stage, the additional subsequent ranking stages will rerank and refine the results further from previous stages .
Modular and Reusable Keyword Search
Anserini
Anserini is an opensource Information Retrieval toolkit in order to solve the reproducibility problems in research and bridge the gap between research and real world systems. This is a tool that is built on top of Lucene, a popular open source search library & enhanced with features specific for conducting IR research. pyserini is a python interface to Anserini.
Indexing
The first challenge faced by the team is representing the Indexable Document. This is fundamental unit of search engine. Results are basically collection of documents. Eg: Tweets, WebPage, Article
One of the common challenge wrt Information Retrieval systems, they tend to favor longer documents. In order to give all documents a fairer chances irrespective of its length, normalization is needed.
The articles are in the following format
{
title : “Impact of Masks”,
abstract: “Masks protects others from you.”
body_text : “Effectiveness of mask /n /n This is being studied …..”
}
In order to compare the effectiveness, the team decide to index the articles in 3 different ways
- Index only the title and abstract of the article as a document
- Index the entire text of the article as a document combining title, abstract and body_text
- Break the body_text of the article into paragraphs and each paragraph as separate documents. In this case, the Indexable Document is title, abstract & the paragraph.
Searching
Once the team built the lucene indices based on the above scheme for CORD-19, we can able to search for a given term, retrieve matching documents and ranked them using BM25 scoring function. These indices are available for the researchers to perform further research.
The full search pipeline for keyword search is demonstrated using notebooks using Pyserini.
In order to provide the users a live system that can be used to answer questions, the team leveraged their earlier work on anserini integration with Solr , open source search platform. The user search interface is built using Blacklight discovery interface with Ruby on Rails for faceting & highlighting.

Highlighting
In addition to that the team also built a highlighting feature on of keyword search. This allows the user to quickly scan the results with the matched keywords in the document.
It is built using BioBERT. The idea behind it is that a) the candidate matched documents & convert them into sentences. b) Similarly the query is treated as a sentence. The sentences & query are in turn converted into its numerical representations (vectors). Top sentences closer to the query are obtained using the cosine similarity. The top-K words in the context are highlighted in these top sentences.
Neural Covidex for reranking
The research group was already working on the neural architectures specifically applying transfer learning on retrieval/ranking based problems.
- BERT for query based Passage Ranking : Applying transfer learning for passage reranking pre-trained on MS-MARCO dataset
- BERTserini for retrieval-based question answering: Incorporating Anserini Retriever to retrieve the top K segments of text followed by BERT based pre-trained model to retrieve the answer span.
Typically the task of reranking is turn the problem into a classification task where we take the query, candidate_document & predict the target as (relevant, not-relevant). To avoid the costly operation of performing classification on the entire corpus, this is applied at the reranking stages. The engine gets the top K documents from the previous retrieval stage and rerank them using machine learning model. As part of reranking stage, the team leveraged Sequence to Sequence Model for reranking (Nogueira et al. 2020).
Stages involved in training the reranking model using Transfer Learning Methodology
Pre-training →Fine Tuning → Inference
- [Pre-training] Transformer based Language Model trained on MS Marco dataset
- [Fine Tuning] Given a query q, document D, the model is fine tuned to predict the output as either true or false as targets indicating the relevance.
- [Inference] In reranking setting, for each candidate documents, predict the prob distribution of (relevant, non-relevant) and sort the scores of relevant doc(true outputs) alone.
Training a language model and the encoder from this fined tuned language model is normally used for the downstream tasks like Classification in transfer learning methodology. But this method of applying Sequence to Sequence model (based on T5) is quite new for document ranking setting (Nogueira et al., 2020).
The reasoning provided was the predicted target words can capture the relatedness through pre-training. This is based on encoder-decoder architecture & uses a similar masked language modeling objective. Given a query, document the model is fine tuned to produce true or false if the document is relevant or not to the query.
Challenges in Results Evaluation
-
The authors rightfully mention that the individual components comprising such a system is evaluated against various test datasets. But as this is specific to an evolving dataset like CORD-19, there is no such existing test collections.
-
It is not always necessary that ranking is the most important for such an end to end system. We have to switch to an outcome based measure rather than a single output based measure like batch retrieval evaluations(MRR, nDCG). Eg: “Did the researchers, practitioners get their questions answered?” How many of them are not finding the answers? So involving human in the loop to qualitatively evaluate the results is essential to know if the system is really contributing towards the efforts fighting the pandemic.
-
What if the exploratory users do not know the right type of keywords to use ? In that case ranking is a wrong goal to pursue.
-
Current challenge is all the targeted users are working on the front line and hard to provide qualitative feedback about search experience. So the author asks for more hallway usability testing to gather insights from the users.
Author Reflections
An end to end system like Covidex is not possible without the power of the current Open Source Software ecosystem, Open culture of curating, cleaning & sharing the data with the community (Thanks to CORD-19 by Allen AI) and pre-trained language models like MS-Marco etc.
Good software engineering practices is the foundation for a team and ensure that the underlying software components can be replicated & reused to provide this system. This is essential to rapidly explore and experiment with new ideas.
Building a strong research culture to produce the results in the form of open source software artifacts aid the community in reproducing the results and build on top of it.
Reminder about the mismatch between producing research code for conference and building a system for a real users. For example concerns like latency of search requests, throughput about the number of users, deploying & managing a system in production, user experience does not arise in a research setting.
Insights & Takeaways from this paper
- Lack of proper training data & human annotators is a common challenge. Leveraging pre-trained models on MS-MARCO is critical for ranking tasks in this type of situation.
- The experimentation mindset need to be adopted and one need to interactive computing tools like pyserini to experiment with search index. This allows the search practitioners to constantly iterate and learn from these experiments.
- Adoption of Openness in not only the source but science and data & the way we work is truly inspiring.